

ReLU 是神经网络界的资本家——只剥削正值劳动力,负值直接失业!Leaky ReLU 是社会主义改造——失业也有低保,但 Swish 试图搞乌托邦,结果大家嫌麻烦。
一、揭开激活函数的面纱
1.1 人工智能世界的"开关"
试着想象我们对家里电灯开关的控制。当我们有足够的光线时,通常不会有打开电灯的行为;当环境光线逐渐变暗至一定程度时,我们会打开它。换句话说,随着“光线”这个因素的变化,我们会采取“激活”或者“不激活”电灯开关两种行为中的一个。
在得出采取哪种行为之前,也许我们还有其他因素的考量,比如:是否需要光线(也许我们正想睡觉)、是否想节省电费(也许觉得电费太贵)、是否有其他因素(也许我们想要一个适合看恐怖片的氛围)等等。在经过种种因素的计算之后,我们会得到一个“想打开电灯开关”的“意愿”。我们将“打开电灯的意愿”将作为输入,传递给一个函数计算之后,最终输出我们“激活开关”或“不激活开关”的行为,而这个得出结论的函数就是早期最简单的激活函数,也被称为“阶跃函数”(Step Function)。
1.2 从阶跃到连续:激活函数的进化史
早期的激活函数决定一个神经元是否应该被激活,就像老式开关,只有开(1)和关(0)两种状态。这种二元决策机制虽然简单,却严重限制了网络的表达能力。而现代激活函数,不仅决定一个神经元是否应该被激活,还决定了神经元被激活信号的强弱。
类比到电灯的例子。我们使用的不再是仅支持“开”或“关”两种选项的电灯,而是额外支持了调节电灯亮度的电灯。出门时,为了节能减排,可以选择关闭电灯;晚上在家吃饭时,需要光线,选择打开电灯;晚上睡觉时,既不希望光线太强影响睡眠,也不希望伸手不见五指,选择打开电灯并调节至微弱亮光。
现代激活函数在神经网络中亦是如此。它像是一个门卫,通过决定上一个神经元的信号是否应该传递给下一个神经元,以及传递信号的强弱程度,控制着信息在神经网络中的流动,是神经网络中重要的组成部分。
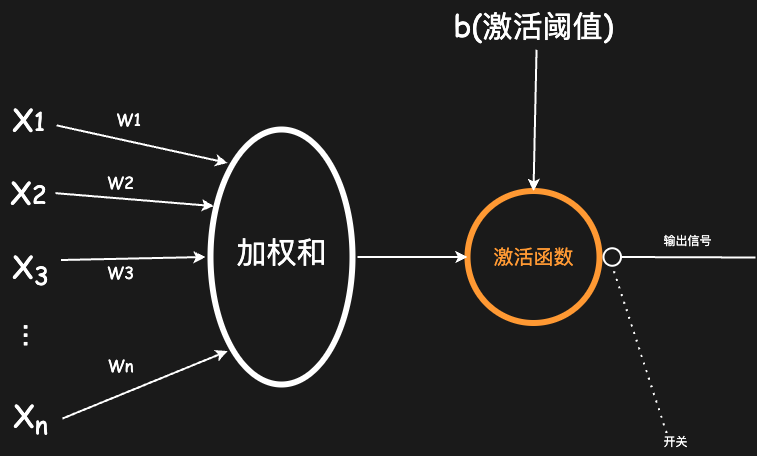
由于早期的激活函数不可导,在深度神经网络中中很少使用,本文以下关于激活函数的描述,除非有特殊说明,否则默认都是指现代激活函数。
现代激活函数的进化轨迹:
- 1958年:感知机使用阶跃函数
- 1986年:Sigmoid函数带来连续可导特性
- 2011年:ReLU函数革命性突破
- 2017年:Swish函数开启自适应时代
- 2020年:GELU成为Transformer标配
二、激活函数的核心价值
2.1 引入非线性魔法🔮
如果不用激活函数,无论深度学习模型有多少层,各层之间都保持着线性关系,这意味着,我们得出的算法只能使用直线来拟合数据。而保持线性关系的各层,实际上可以只用一个层代替,深度学习也失去了“深度”的意义。

根据通用近似定理(Universal Approximation Theorem):仅需单隐藏层+适当激活函数,即可逼近任何连续函数。
使用激活函数,则在模型的各神经元之间中引入了非线性关系,使得网络具备了可以拟合任意复杂函数的能力。
2.2 影响梯度计算🧠
激活函数的可微性为反向传播提供了必要基础,实际上,也可以说是为了要确保反向传播正常运行,所以激活函数必须具备可微性。总之,激活函数的使用也确保了拟合数据的算法在分段可微或存在次梯度,从而让反向传播算法可以正常计算出各权重的梯度,进而通过梯度信息确定权重和偏置的优化方向。
以ReLU函数为例
$$ \text{ReLU}(x) = \begin{cases} x, & \text{if } x > 0 \\ 0, & \text{if } x \leq 0 \end{cases} $$ReLU的导数非常简单。对于正输入值,梯度为1;对于负输入值,梯度为0。这种简单的梯度计算方式不仅减少了计算量,还避免了由于复杂导数计算可能引起的数值问题。
2.3 适配不同任务🎬
除了以上两个至关重要的用处,激活函数还用于控制输出的数据范围,以适应不同训练任务的场景,如:
- sigmod函数将输出范围控制到(0, 1),可用于表示二元分类任务的概率分布
- Softmax函数所有输出的和为1,可用于表示多分类任务的概率分布
2.4 促进稀疏激活💡
部分激活函数用于控制神经元是否需要激活,通过将不必要的神经元关闭(置零),模拟生物神经元,只在必要的时候激活,以实现稀疏激活,提高计算效率,如ReLu函数的置零效应。
2.5 其他优化功能➡️
随着激活函数技术的不断进化,部分激活函数还提供了不少额外的优化功能,如缓解梯度消失、梯度爆炸等。截至今日(2025年春),许多新的激活函数仍在不断衍生,如Swish、GELU等函数,还通过自适应门控机制则更进一步优化了梯度流动与非线性表达能力;Dynamic ReLU则根据输入动态调整斜率,使神经网络自适应不同数据模式….
综上所述,激活函数作用包括但不限于以下几点:
- 引入非线性,使神经网络能拟合更复杂的数据
- 确保反向传播算法可以正常运行,以及减少计算梯度的计算量
- 控制输出范围,适配不同训练需求
- 促进稀疏激活,提高训练效率
- 其他新的优化功能,如缓解反向传播中梯度消失/爆炸等
三、激活函数的选择
关于激活函数如何选择,以及选择的参考,都具有时间局限性,以下内容基于截至2025年春季的技术认知和个人主观判断,阅读时,敬请多加甄别。此外,如果有兴趣,建议关注最新的激活函数技术以及未来发展方向。
3.1 激活函数四维决策框架🧾
尽管部分场景下,激活函数之间可以替换使用,但激活函数在深度学习中的选择,仍是训练深度学习模型过程中的重要步骤之一。选择一个合适的激活函数,可以让模型的拟合效果更佳、让训练的效率更高,可以减少不必要的时间、人力成本。
在选取激活函数时,我们可以考虑包括但不限于以下四个维度:
- 使用位置
- 隐藏层:ReLU及其变体(大部份场景)、GELU(Transformer)
- 输出层:Sigmoid(二分类)/Softmax(多分类)/Linear(回归)
- 任务类型
- CV领域:优先尝试ReLU
- NLP领域:GELU表现更佳
- 强化学习:Tanh更适合动作空间
- 工程考量
- 训练速度:ReLU > Leaky ReLU > Swish
- 内存消耗:ELU > SELU > ReLU
- 对症下药
- 梯度消失:换用ReLU/Swish
- 死亡神经元:尝试Leaky ReLU(α=0.01)
- 梯度爆炸:配合权重初始化+BN层
- 训练震荡:试试SELU+AlphaDropout
3.2 2024年主流激活函数性能天梯🪜
粗略列举,主要为了更直观地展示激活函数的选取,带有时间局限性和个人主观性,请加以甄别
| 函数名称 | 训练速度 | 收敛稳定 | 创新指数 | 适用场景 |
|---|---|---|---|---|
| ReLU | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | 通用CV |
| GELU | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Transformer |
| Swish | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 大模型 |
| Mish | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 目标检测 |
| LeakyReLU | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | GAN判别器 |
四、给自己的一些建议🤔
- 通过实践了解不同激活函数的适配场景,根据不同场景选取合适的激活函数
- 基础架构优先选择ReLU及其变种
- 新项目建议尝试GELU+Swish组合
- 保持对AutoML研究的关注,及时跟进NAS发现的创新激活形式
- 重要项目可先进行激活函数消融实验(ablation study)
"没有最好的激活函数,只有最合适的场景组合"。在这个每天都有新突破的AI时代,激活函数的选择既是科学也是艺术。理解其本质原理,保持开放思维,持续关注新的激活函数技术。改变规则的激活函数,或许就出现在下一个版本。
Comments NOTHING